
I’m fascinated with the idea of automating myself out of a job.
Throughout my career, I’ve done a lot of server maintenance. I’ve seen firsthand what happens when you don’t update often. I know how painful it is to do multiple “catch-up” upgrades for older software.
Over the past five years, open source containerization has dominated the industry, and there are no signs of slowing down.
We’re at the point now that we’ve abstracted most of the “sharp edges” around application development. Today, applications are less reliant on the underlying hardware. Kubernetes is the abstraction layer that helps applications just work™
That got me thinking about the next evolution for cloud-native practitioners.
I posted a silly question on Twitter about “turning on all the automation.”
Tell me what I'm missing:
— Jim Angel (@JimmAngel) August 22, 2020
☑️ 3 node cluster
☑️ Ubuntu w/ live patch
☑️ unattended upgrades for entire OS, docker, and kube bits
☑️ Monit watching daemons
☑️ Self updating flux controller, CNI, etc.
☑️ Cron running kubeadm upgrade(s)
How many upgrades will it survive? 😁
In this proposal, the cluster would self-upgrade, and GitOps would update applications, including itself. High-level overview:
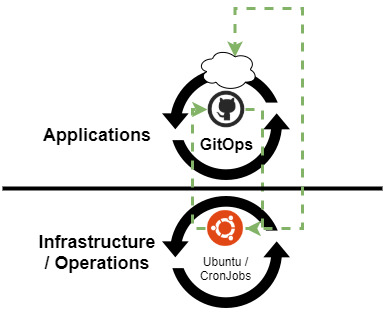
Or more detailed:
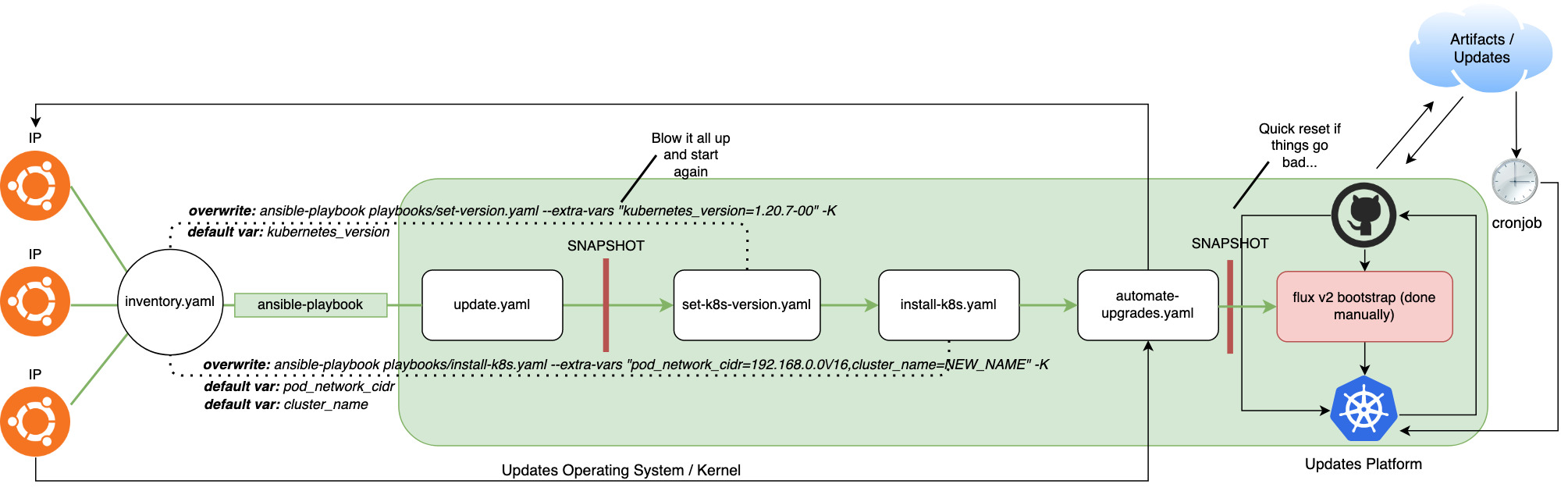
Note
There’s so much that could go wrong with this. I should remind everyone that this is for fun and NOT production. Upgrades could conflict, packages could break dependencies, releases could be tainted, etc.
I wanted to try this using local VMs. So I spun up 3 Ubuntu VMs on VMware Workstation. It seems like cheating to use a cloud provider for auto-patching.
In my first attempt, I built the cluster using kube-spray because it’s production ready with more “batteries included.” The “batteries included” obscured some of the configuration, which later bit me.
I did it and it **kinda** works. The biggest problem I had is flux auto-updating to the wrong tag.
— Jim Angel (@JimmAngel) September 12, 2020
The cluster auto-upgraded to 1.19.1 without me touching it. Same for the kernel.
Details: https://t.co/PSZ07Vlvqw https://t.co/qa2t9JNw3Q
isitstillrunning.com
Once the infrastructure was stable-ish and auto-updating, I launched a website: isitstillrunning.com, to track the cluster’s progress. A script on the control plane would scrape the node and commit the data back to GitHub daily (which then triggers a website build).
The cluster ran for eight months and survived two major releases and a handful of patch releases! 🎉
However, I made some mistakes when configuring kubespray, and I had to redo the entire project in June of 2021 after everything broke. It wasn’t only kubespray; it was also:
The 2021 Texas Power Crisis
In mid-February of 2021, central Texas lost power for a week, impacting millions. I was without power and water for five days which was longer than the cluster’s DHCP leases. Each node in the cluster received a new IP. 🤦
https://t.co/PSZ07Vlvqw? No.
— Jim Angel (@JimmAngel) March 17, 2021
Why? Rookie mistake(s). My demo local cluster used DHCP and lost their leases when I lost power for a week in Texas.
It get's worse; I originally created two control-plane nodes with local etcd. This means if I lose one etcd member, I lose quorum 🤦♂️ pic.twitter.com/kIp2puddcE
Below is the final screen grab before I took the cluster offline. The gap on the right side are when the script fails due to the lack of a working Kubernetes cluster.
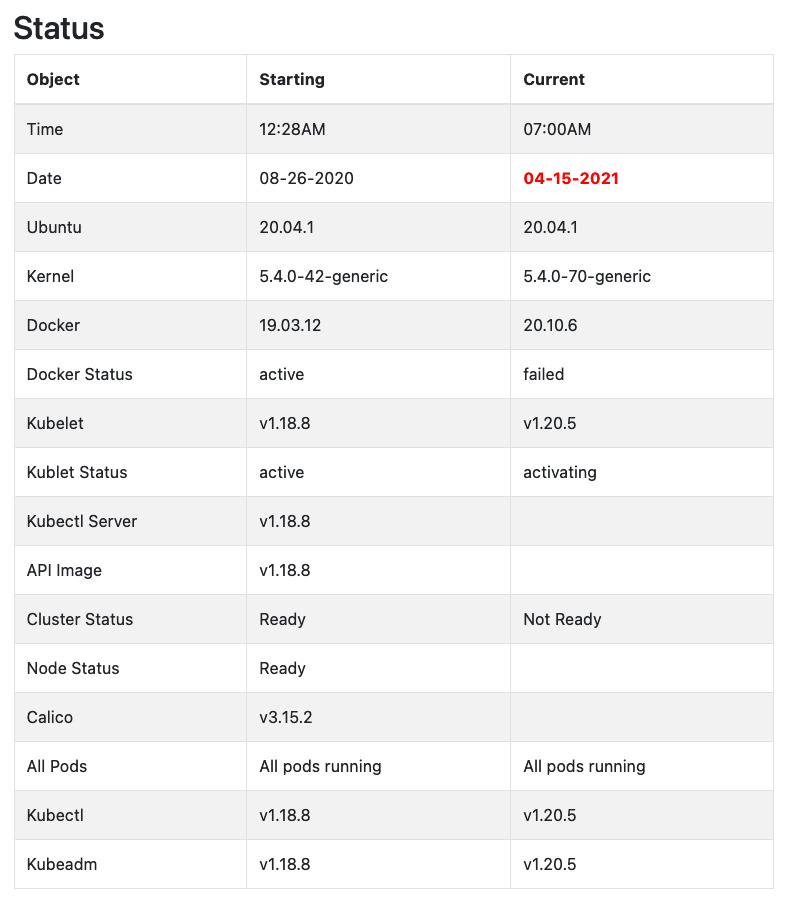
We can rebuild it
With a fresh slate, I automated most of what I did. Automating the build helps for rebuilding after future failures. A couple of changes and “lessons learned” that I’m going to add:
- Use reserved/static IPs
- Take etcd backups
- Use Flux v2 (more of a toolkit then an operator)
- Take Calico out of flux, apply the Calico CNI file often
- Leverage more
helmand lesskustomizefor automation
It would have been great to have Calico auto-update based on image tags or repositories, but it became more complex than it was worth for this project. Let me know if you have thoughts on how to handle the CNI better!
Create the cluster
I wrote my own Ansible playbooks because I want know my cluster’s exact configuration. I also tried to make the playbook easy to read and update. By leveraging Ansible, my future changes and maintenance will be a lot easier.
The Ansible scripts work on any OS, but for this project, I’m using Ubuntu 20.04 LTS VMs.
I’m using Ubuntu for (free) Canonical Livepatch Service which I use to keep our kernel up to date.
Set static IPs
Let’s avoid having a natural disaster turn into a technical one. This depends on how your network is configured. I use a router from Unifi and can set static IPs through the UI.
Setup Ansible config and access
I broke the playbooks into phases that I thought could be reusable chunks. For example, there’s a playbook for general bootstrap and another for specific version pinning. Each playbook acts as a foundation to the next layer.
The playbooks are publicly available in the kubeleak repository on GitHub.
Note
The following commands are tested on Ubuntu 20.04 only.
- Install Ansible
- Copy SSH keys to each of the nodes
- Verify a key exists or create one.
ssh-copy-id USER@NODE_IP_ADDRESS_1ssh-copy-id USER@NODE_IP_ADDRESS_2ssh-copy-id USER@NODE_IP_ADDRESS_3
Clone the kubeleak repository.
git clone git@github.com:jimangel/kubeleak.git
Update inventory.yaml by replacing the IP addresses with your node IPs
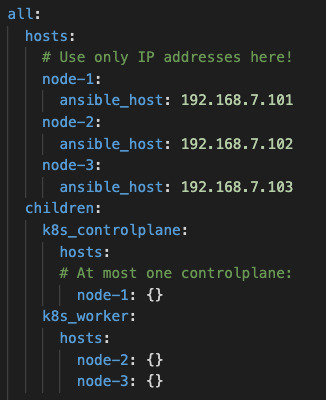
Also replace the remote_user with the USER on the remote VMs.
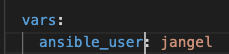
Once finished, test the connections by running:
ansible all -m ping
If it all comes back successful, you’re ready to go!
Playbook-1: Update everything and snapshot
If interested in what’s installed, look at playbooks/update.yaml. I borrowed much of this playbook from linuxsysadmins.com
The first playbook gets us to a “clean slate” by running updates on all the machines and installing the necessary repos / components.
ansible-playbook playbooks/update.yaml -K
The -K forces Ansible to ask you to type the password for sudo, “the BECOME password.” An alternative would be to add your user to the WHEEL file so it never prompts for a password.
To summarize what’s happening:
aptupdate everything- disable swap
- remove swap
- install Kubernetes pre-reqs & packages
- install Docker
- ensure Docker is running
- ensure Kubelet is running (and failing…)
- reboot
Once complete, let’s take a snapshot of the VMs to revert at any point. This is also helpful if I ever want to create a node template.
Playbook-2: Force version of Kubernetes and components
I’m going to install one minor version to see if the automation and updates work. By default, the script takes the value from inventory.yaml.
ansible-playbook playbooks/set-k8s-version.yaml -K
You can also look up and specify a version of k8s.
# `apt-cache madison kubeadm | grep 1.20`
ansible-playbook playbooks/set-k8s-version.yaml --extra-vars "kubernetes_version=1.20.7-00" -K
Be careful running this on existing clusters. Running a mix-matched version of utilities is not recommended. Always ensure your tools stay within the version skew.
Playbook-3: Install Kubernetes
I created a kubeadm template which acts as the main driving configuration for Kubernetes. If you open templates/kubeadm-config.j2 up, you can see there are a lot of parameters for Kubernetes.
Kubeadm doesn’t support changing any parameters while upgrading, so getting right from the start is essential.
ansible-playbook playbooks/install-k8s.yaml -K
In a few minutes, you’ll have a cluster!

Manually: Configure Flux v2 and Kubernetes
Log in to the control plane node as your user.
Once logged in, kubectl should already be configured.
Create etcd Prometheus secret
Prometheus is included in my GitOps stack; let’s make sure it can scrape etcd by creating the authentication certificate as a secret.
# Creates secret for Prometheus scraping
sudo kubectl --kubeconfig="/etc/kubernetes/admin.conf" -n monitoring create secret generic etcd-client-cert --from-file=/etc/kubernetes/pki/etcd/ca.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key
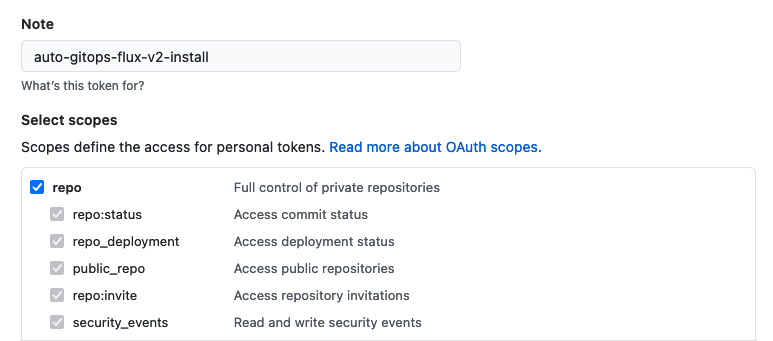
Create a GitHub Token
Before setting up Flux, let’s create a GitHub Token to use. A token is needed for read/write access to your GitOps repo. The documentation indicates the token needs full repo access.
Next export the information for flux CLI to use.
export GITHUB_TOKEN=<your-token>
export GITHUB_USER=<your-username>
Setup Flux v2
The easiest way to do that is using their flux CLI.
curl -s https://fluxcd.io/install.sh | sudo bash
# enable completions in ~/.bash_profile
. <(flux completion bash)
flux bootstrap is supposed to be idempotent and either create or pull a repo, depending on its existence. Once set up, the CLI can do more. Check out the official docs!
flux bootstrap github \
--owner=$GITHUB_USER \
--repository=auto-gitops-v2 \
--branch=main \
--path=./clusters/isitstillrunning \
--components-extra=image-reflector-controller,image-automation-controller \
--personal
I did a TON of work to automate my flux deployments. It could almost be another post. If you’re interested in looking at the repo, click here.
Playbook-4: Configure auto-updates
The last and final playbook. It’s a simple one to install unattended-upgrades for the OS.
ansible-playbook playbooks/automate-updates.yaml -K
The defaults cover the OS but don’t include Docker and Kubernetes. To add Docker and Kubernetes, edit /etc/apt/apt.conf.d/50unattended-upgrades on each node to include the following 2 lines under Unattended-Upgrade::Allowed-Origins {:
"kubernetes-xenial:kubernetes-xenial";
"Docker:focal";
If you want to test it out, you can; however, keep in mind that you’re upgrading everything.
sudo unattended-upgrade –dry-run –debug
Crontab scripts
Since kubectl, kubeadm, kubelet, and docker are automatically updated, I wrote a crude script to try to get kubeadm to upgrade the control plane by using the new versions. As root, ad the following contents to /etc/upgrade-node.sh
# remove version from config file
sudo sed -i '/kubernetesVersion/d' /etc/kubeadm-config.yaml
kubeadm upgrade apply -y --config=/etc/kubeadm-config.yaml --ignore-preflight-errors=all --etcd-upgrade=true --force
sudo service docker restart
sudo service kubelet restart
Make executable chmod +x and schedule.
crontab -e
0 12 * * * /etc/upgrade-node.sh > /tmp/kubeadm.log 2>&1
Configure git:
git config --global user.email "node1@localhost"
git config --global user.name "node-1"
As your user, add the following contents to /etc/status-node.sh
#!/usr/bin/env bash
cd /home/jangel/go/src/github.com/jimangel/isitstillrunning.com/
git pull
git reset --hard HEAD
NUM_NODES=3
cat << EOF > /home/jangel/go/src/github.com/jimangel/isitstillrunning.com/data/current.yaml
time: $(TZ=":US/Central" date +%I:%M%p)
date: $(date +"%m-%d-%Y")
ubuntu: $(cat /etc/os-release | grep VERSION= | awk -F'"' '{print $2}'| awk '{print $1}')
kernel: $(uname -r)
docker: $(docker -v | awk -F, '{print $1}' | awk '{print $3}')
docker_status: $(systemctl status docker --no-pager | grep Active | awk '{print $2}')
kubelet: $(kubelet --version | awk '{print $2}')
kublet_status: $(systemctl status kubelet --no-pager | grep Active | awk '{print $2}')
kubectl_server: $(kubectl --kubeconfig="/home/jangel/.kube/config" version --short | grep Server | awk '{print $3}')
api_images: $(kubectl --kubeconfig="/home/jangel/.kube/config" get pods -o yaml -n kube-system | grep "image:.*apiserver" | sort -u | awk -F: '{print $3}' | paste -s -d, -)
cluster_status: $(if [ "$(kubectl --kubeconfig="/home/jangel/.kube/config" get nodes | grep Ready -c)" == "$NUM_NODES" ]; then echo "Ready"; else echo "Not Ready"; fi)
node_status: $(kubectl --kubeconfig="/home/jangel/.kube/config" get nodes -o wide | grep $(hostname) | awk '{print $2}')
calico: $(kubectl --kubeconfig="/home/jangel/.kube/config" get daemonsets -n kube-system calico-node -o yaml | grep "image: docker.io/calico/cni" | sort -u | awk -F: '{print $3}')
all_pods: $(if [ "$(kubectl --kubeconfig="/home/jangel/.kube/config" get pods -A | awk '{if(NR>1)print}' | grep -v "Running\|Completed\|Evicted")" == "" ]; then echo "All pods running"; else echo "Not all pods running"; fi)
kubectl: $(kubectl --kubeconfig="/home/jangel/.kube/config" version --short | grep Client | awk '{print $3}')
kubeadm: $(kubeadm version -o short)
EOF
git add /home/jangel/go/src/github.com/jimangel/isitstillrunning.com/data/current.yaml
git commit -m "Updating current data $(date +'%m-%d-%Y')"
git push -u origin
# check for a new CNI
curl -s https://docs.projectcalico.org/manifests/calico.yaml \
| sed 's/# - name: CALICO_IPV4POOL_CIDR/- name: CALICO_IPV4POOL_CIDR/' \
| sed 's/# value: "192.168.0.0\/16"/ value: "172.16.0.0\/12"/' > /tmp/calico.yaml \
&& kubectl --kubeconfig="/home/jangel/.kube/config" apply -f /tmp/calico.yaml
Make executable chmod +x and schedule.
crontab -e
0 12 * * * /etc/status-node.sh 2>&1
LivePatch
Lastly, I enabled LivePatch to auto-patch the kernel.
Conclusion
I’m glad to be up and running. Building the automation took me longer, but I hope it opens up for future fast iterations. I’m not entirely sure my Flux configuration is optimal. I might consider trying out Argo, an alternative GitOps engine.
There’s a lot of work above that could have been automated, and I might; when I revisit this.
My next steps are:
- Ensure updates are working as intended
- Add more security around pulling in things from the public
- Configure velero for backups
- Look into rotating Flux keys
- Look into integrating secrets with my GitOps strategy (Sealed Secrets / SOPS)
As issues pop up with the cluster, I’ll update this post! Cheers!